AI data collection tools, such as GPTBot, are on the rise, posing new challenges in bot protection and prevention. This article explores the increase in undisclosed AI parsing, the lack of supervision behind it, and ways to protect against unauthorised data harvesting while ensuring a good user experience. To address this challenge, website owners can employ rate limiting, utilise a robots.txt file, and implement selective IP bans with trusted blocklists.

Artificial intelligence (AI) has become more accessible in recent years, leading to new opportunities for innovation and efficiency, but also highlighting the need for robust website bot mitigation techniques. This increased usage of AI has also brought about challenges in protecting websites from scraping and data misuse by AI-powered bots. This article will discuss the common best practices for protecting your website(s) against unauthorised AI scraping.
The Rise of AI Scraping
One notable AI development that has made headlines is GPTBot, an AI crawler developed by OpenAI. GPTBot plays a pivotal role in collecting real-time data, which is then used to train OpenAI's ChatGPT language model. This enables ChatGPT to generate relevant text and images based on user requests. However, it's important to note that GPTBot can have unintended negative consequences if not managed carefully.
According to our data, in some cases GPTBot accounted for up to 90 percent of the traffic to online shops' websites in Q3 2023. While GPTBot is a legitimate tool developed by a reputable organisation, its unchecked requests can impose a heavy load on servers and consume significant resource capacity. This can be detrimental to a website's performance, underlining the importance of bot protection and bot mitigation software.
AI Data Collection Beyond GPTBot
GPTBot is just the tip of the iceberg when it comes to AI data collection. Numerous commercial services, startups, and AI assistants leverage various language models, some even utilising pirated ones. What is common to all of them is that they require lots of information to stay fast and relevant for their customers.
This raises the question: where do these entities source their data? While established organisations like OpenAI have partnerships that grant them access to data, smaller startups often resort to web scraping as their primary data source.
Many AI parsers operate under the radar, and their activities often go unnoticed by the general public and website owners. These parsers do not voluntarily introduce themselves, as they aim to avoid being banned or detected.
Possible Preventative Measures
In an ideal world, many of these issues could be resolved through regulations that ensure fair and accurate data usage. Unfortunately, AI currently lacks substantial regulatory oversight. As a result, companies often operate with considerable freedom, as there are no technical requirements obligating them to adhere to specific standards.
Even as regulations begin to take shape, there remains uncertainty about whether these companies will willingly comply, given the ease with which such regulations can potentially be circumvented.
However, that said, we have compiled two lists: one outlining actions that we strongly recommend companies take, and another highlighting practices that we generally advise against due to the potential broader implications that they may entail.
Things That You Should Do
Implement Rate Limiting: To effectively deter AI scraping bots, it's crucial to establish rate limiting as a fundamental protection measure. Rate limiting sets a baseline defence by throttling the number of requests allowed from a single source. This enables you to control the pace of data retrieval and reduce the risk of data misuse. While this technique is not a be-all- and end-all of your countermeasures, it may help save your server from excessive loads Remember: the greediest of bots will try to collect data from you at the highest possible rate if you allow them.
Utilise Selective IP Bans: When necessary, consider implementing selective IP bans for addresses associated with egregious scraping activities. Maintain current blacklists from reputable sources like FireHOL to more effectively identify and target IPs with a known history of malicious activities. This balanced approach allows you to block high-risk threats while avoiding false positives.
Things That You Shouldn’t Do
Avoid Blanket IP Bans: Resist the temptation to implement indiscriminate IP bans. Blanket bans, if not carefully managed, can inadvertently block legitimate users, including those who rely on virtual private networks (VPNs) or proxies for various reasons. Such overzealous blocking can significantly degrade user experience and damage your website's reputation.
Use Caution With Web Protection Services: Exercise caution when using web protection services to ensure they do not create excessive waiting times for users. Striking the right balance between security and user experience is crucial. Over reliance on these services can lead to user frustration and negatively impact your website's usability.
Configuring Your Robots.txt
As a final measure, adding restrictions to your robots.txt file can be an effective strategy against unauthorised scraping. This simple text file gives instructions to well-behaved crawlers about which pages or sections of your site should not be accessed or indexed. While not failproof, a robots.txt file can deter scraping from many crawlers and better-behaved data mining operations.
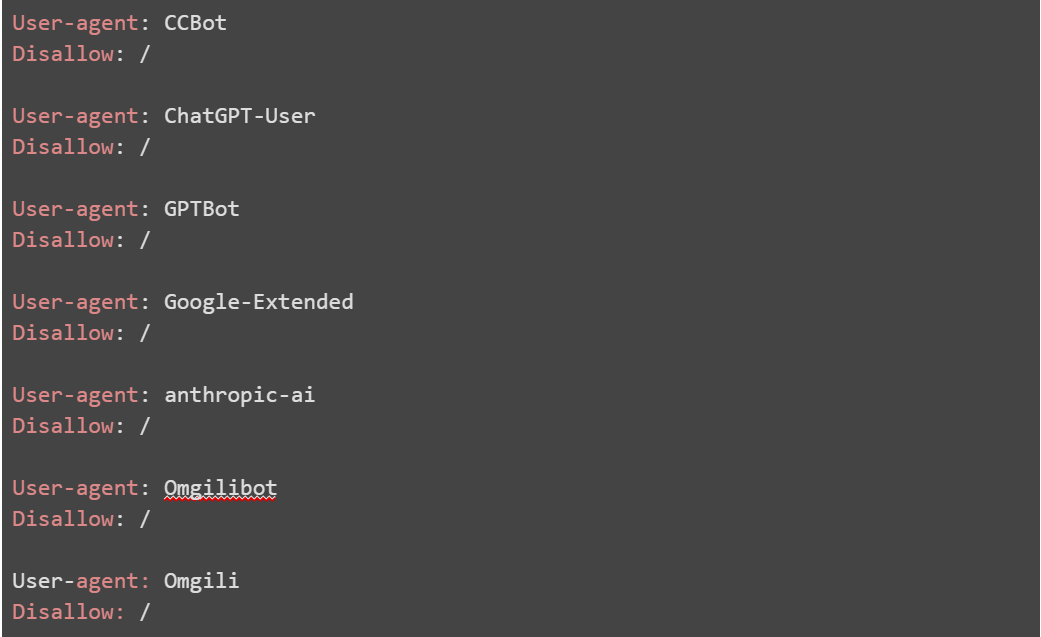
Above you can find all of the publicly identifiable AI scrapers that we have found which you can block. However, it’s important to note this method only works for scrapers that are programmed to respect the file, so it’s definitely not a fix-all solution.
Embrace Comprehensive Bot Protection with Qrator Labs
Secure your digital assets with Qrator Labs today.
Don't wait any longer to join our satisfied clients who have experienced the remarkable impact of our Qrator.Antibot solution, which has successfully blocked over 4 billion monthly bot requests, reduced bot traffic on websites by an impressive 23%, and lowered the average business loss by 9.2%.
Take the next steps towards protecting your business from threats like account takeover, scraping, credential stuffing, and server overloading.