TL;DR: Client-server architecture of our internal configuration management tool, QControl.
At its basement, there’s a two-layered transport protocol working with gzip-compressed messages without decompression between endpoints. Distributed routers and endpoints receive the configuration updates, and the protocol itself makes it possible to install intermediary localized relays. It is based on a differential backup(“recent-stable,” explained further) design and employs JMESpath query language and Jinja templating for configuration rendering.
Qrator Labs operates on and maintains a globally distributed mitigation network. Our network is anycast, based on announcing our subnets via BGP. Being a BGP anycast network physically located in several regions across the Earth makes it possible for us to process and filter illegitimate traffic closer to the Internet backbone — Tier-1 operators.
On the other hand, being a geographically distributed network bears its difficulties. Communication between the network points-of-presence (PoP) is essential for a security provider to have a coherent configuration for all network nodes and update it in a timely and cohesive manner. So to provide the best possible service for customers, we had to find a way to synchronize the configuration data between different continents reliably.
In the beginning, there was the Word… which quickly became communication protocol in need of an upgrade.
The corner point of QControl existence and the main reason for spending a lot of time and effort into building such a protocol of ours is a need to get one authoritative source of the configuration and eventually synchronize our PoPs with it. Storage was only one of several required features of the QControl development. Besides that, we also needed integration with the existing and future periphery, smart (and customizable) data validations, and access differentiation. Furthermore, we wanted this system to manage things through commands, not through manual file modifications. Before QControl, data was sent to the points-of-presence more or less manually. If some PoP was unavailable at the moment, and we forgot to update it later, configuration got desynchronized, and time-consuming troubleshooting was needed to bring it back in sync.
Here’s the system we came up with:
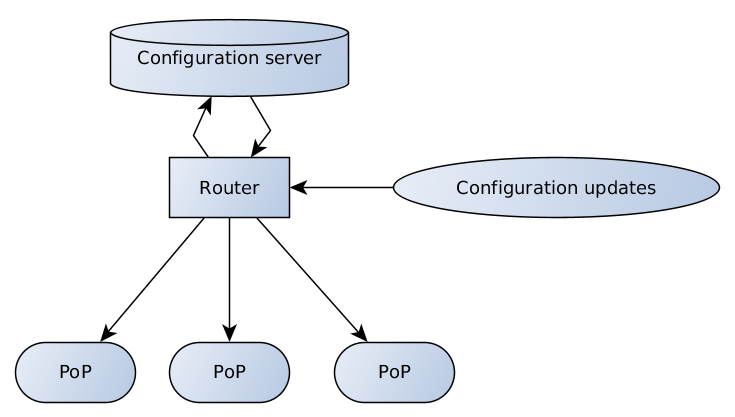
The configuration server is responsible for data validation and storage; the router has different endpoints to receive and relay configuration updates from clients and support team to server and from server to PoPs.
Internet connection quality is still quite diverse all over the globe — to illustrate this, let’s visualize a simple traceroute from Prague, the Czech Republic to Singapore, and Hong Kong.

MTR from Prague to Singapore

Same second screenshot with traceroute to Hong Kong
High latency numbers mean poor speed. Also, there is a high packet loss. Bandwidth numbers do not compensate for this problem, that should always be taken into consideration when building decentralized networks.
The full PoP configuration is a rather significant chunk of data and needs to be transferred to many different receivers over unreliable connections. Luckily, although configuration changes frequently, it changes in small increments.
Recent-stable design
It’s a quite straightforward decision to build a distributed network based on incremental updates. Though there are quite some problems with the diffs, they are difficult to build correctly: we have to save all the diffs between reference points somewhere, to be able to resend them if someone lost something. Every destination should apply them coherently. In case there are several destinations, this could take much time across all the network. The addressee should also be able to request missing parts, and of course, the central part must answer such request accurately, sending only the missing data.
What we have built in the end is quite a thing — we have only one reference layer, the fixed “stable” one, and only one diff, “recent” for it. Every recent is based on the latest stable and is sufficient to rebuild configuration data. When a new recent reaches destination, the old one is disposable.
It leaves us with the need sometimes to send a new stable configuration because the recent grow too big. Also, an important note here is that we can make all this by broadcasting/multicasting updates, not worrying about receiving destinations ability to assemble the pieces. Once we check that everyone has the right stable, they are all fed with just the fresh recent. Should we say that it works? It does. Stables are cached at the configuration server and the receivers, with the recent recreated when needed.
Two-layered transport architecture
Why exactly have we built our transport out of two layers? The answer is pretty simple: we wanted to split up routing from the application, taking inspiration in the OSI model with its transport and application layers. So we’ve separated the transport protocol (Thrift) from the high-level command (msgpack) serialization format. That is why a router (which does multicast/broadcast/relay) neither look inside the msgpack, nor extracts or compresses the payload and does only the transmission.
Thrift wiki:
Apache Thrift allows you to define data types and service interfaces in a simple definition file. Taking that file as input, the compiler generates code to be used to easily build RPC clients and servers that communicate seamlessly across programming languages. Instead of writing a load of boilerplate code to serialize and transport your objects and invoke remote methods.
We took the Thrift framework because of its RPC and multiple language support at once. As always, the easy parts are easy to build: the client and the server. However, the router was quite a hard nut to crack, in part due to the absence of a ready-to-use solution at the time.
 There are some other options, like the protobuf / gRPC, though when we started with our project, the gRPC was immature and we hesitated to use it.
There are some other options, like the protobuf / gRPC, though when we started with our project, the gRPC was immature and we hesitated to use it.
Of course, we could (and should!) create a wheel of our own. It would be easier to create a custom protocol for what we need, along with the router because the client-server is more straightforward to program than making a working router with Thrift. However, there’s traditional negativity towards custom protocols and implementations of popular libraries, and there’s always the “how do we port it afterward into other languages.” So we decided to drop the wheely ideas.
Msgpack description:
MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON. But it's faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves.
At the first layer, we have a Thrift with the minimum information needed for the router to send a message. On the second layer, we have сompressed msgpack structures.
We voted for the msgpack because it’s faster and more compact compared to JSON. However, what’s even more important, is that it supports custom data types, allowing for some exciting features like “white-outs” and raw binary data transfer.
JMESPath
JMESPath is a query language for JSON.
That is the only description we get from the official JMESPath documentation, but actually, it’s much more than just that. JMESPath allows to search and filter arbitrary tree-like structures and even apply data transformations on the fly. We use this query language to get relevant information from the large configuration blob.
While the whole configuration has a tree-like structure, we extract the relevant sub-trees for different configuration targets.
It’s also flexible enough to change the sub-tree, independently of a config template or other config plugins. To make it even better, JMESPath is easily extensible and allows to write custom filters and data transformation routines. It needs some brainpower to comprehend, though.
Jinja
For some targets, we need to render the configuration into files, so we needed a template engine, where Jinja is an obvious choice. Jinja is generating a configuration file out of the template and the data received at the destination point.
To render the config file, we need a jmespath request, template for path and destination file, template for the config itself. Also, at this point, it’s good to specify the file access rights. All this got luckily combined in one file — before the config template, we put a YAML header, describing the rest. For example:
---
selector: "[@][?@.fft._meta.version == `42`] | items([0].fft_config || `{}`)"
destination_filename: "fft/{{ match[0] }}.json"
file_mode: 0644
reload_daemons: [fft]
...
{{ dict(match[1]) | json(indent=2, sort_keys=True) }}
To make the config for a new periphery, we add a new template file, no source code changes and PoP software updates are needed.
What has changed after implementing the QControl configuration management tool?
First and foremost, we got coherent and reliable configuration updates over all our network.
Second, we put powerful tool for configuration validation and change into the hands of our support team and our clients.
We’ve accomplished this by employing recent-stable design to simplify communication between the configuration server and configuration recipients, by using two-layer communication protocol to support payload-agnostic routers and by implementing the Jinja-based configuration rendering engine to support a wide variety of configuration files for our diverse periphery.