
October 4, 2021, has all the chances to become a BGP awareness day.
Memes aside, yesterday, with the entirety of its ecosystem including vast resources like Instagram and WhatsApp, Facebook disappeared from the Internet.
Such events do not happen quite often. In part, because the Internet architecture has significant fault tolerance, mainly thanks to the BGP, and partly because usually big companies, with, say, a billion users, do not centralize their resources in a way that could prompt a 100% unavailability across networks.
Yet, yesterday Facebook and all associated resources experienced a massive network outage. Let’s go through what we saw in the world of BGP.
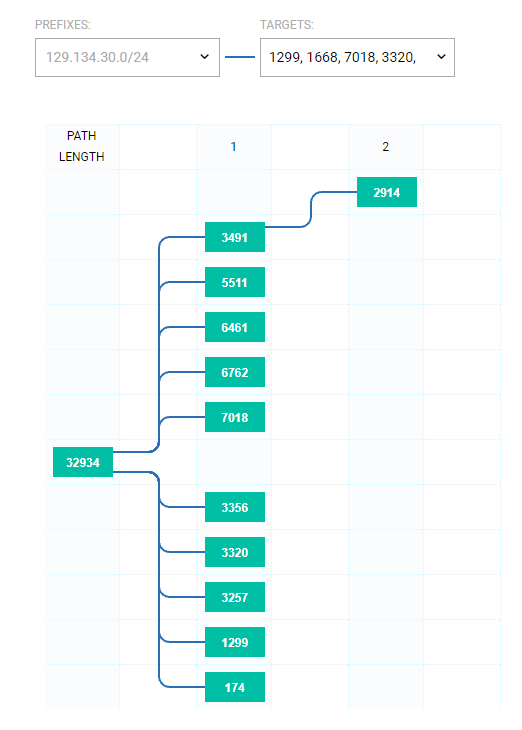
That is how normally (October 5, 9:30 snapshot) an AS path looks like for the prefix 129.134.30.0/24, covering one of the Facebook DNS nameservers.
Yet, yesterday, starting at 15.40 UTC, they were withdrawn from the announcement, making those effectively unreachable for DNS service.
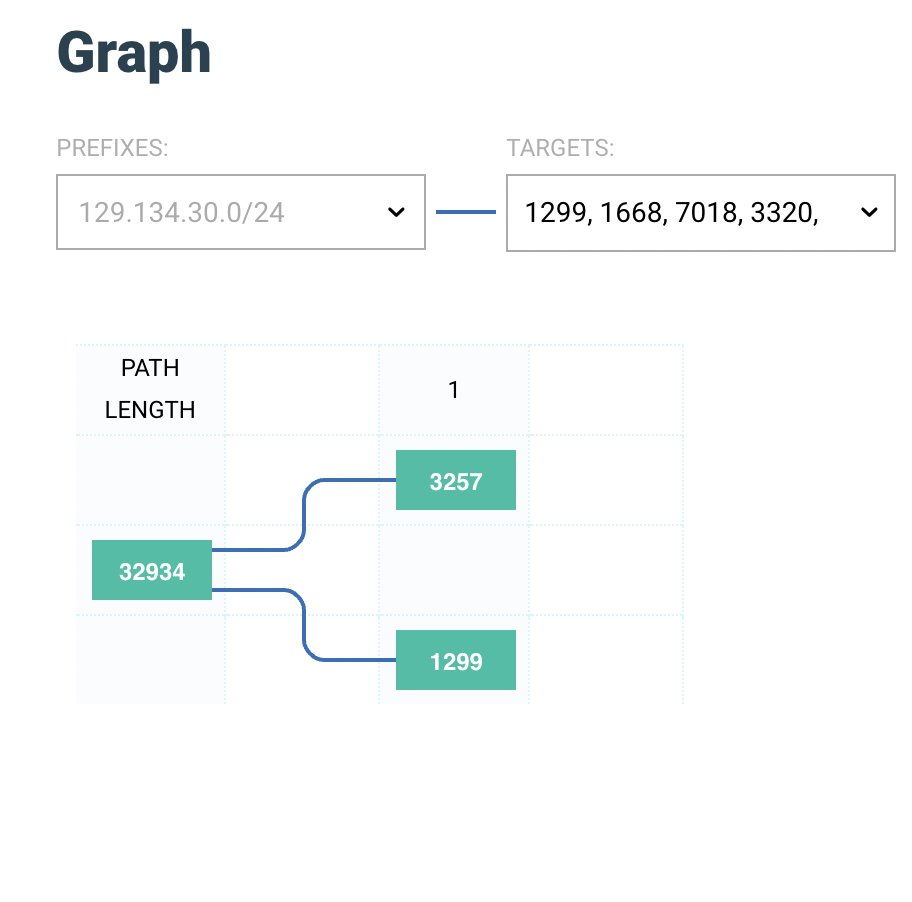
Along with two other network prefixes: 129.134.30.0/23, 129.134.31.0/24, those three in combination contain all four nameservers of Facebook’s ecosystem of social networks and other services.
We looked at the A and B name servers during the incident, not the C and D, although now, all of them point at the IP addresses that were included in withdrawn prefixes after the incident.
The amount of withdrawn IPv4 prefixes was a bit larger than two /24 and one /23:
'129.134.25.0/24', '129.134.26.0/24', '129.134.27.0/24', '129.134.28.0/24', '129.134.29.0/24', '129.134.30.0/23', '129.134.30.0/24', '129.134.31.0/24', '129.134.65.0/24', '129.134.66.0/24', '129.134.67.0/24', '129.134.68.0/24', '129.134.69.0/24', '129.134.70.0/24', '129.134.71.0/24', '129.134.72.0/24', '129.134.73.0/24', '129.134.74.0/24', '129.134.75.0/24', '129.134.76.0/24', '129.134.79.0/24', '157.240.207.0/24', '185.89.218.0/23', '185.89.218.0/24', '185.89.219.0/24', '69.171.250.0/24'
These IPv4 addresses combine into two /16 network prefixes containing NS servers.
Also, there were several IPv6 prefixes withdrawn:
'2a03:2880:f0fc::/47', '2a03:2880:f0fc::/48', '2a03:2880:f0fd::/48', '2a03:2880:f0ff::/48', '2a03:2880:f1fc::/47', '2a03:2880:f1fc::/48', '2a03:2880:f1fd::/48', '2a03:2880:f1ff::/48', '2a03:2880:f2ff::/48', '2a03:2880:ff08::/48', '2a03:2880:ff09::/48', '2a03:2880:ff0a::/48', '2a03:2880:ff0b::/48', '2a03:2880:ff0c::/48', '2a03:2881:4000::/48', '2a03:2881:4001::/48', '2a03:2881:4002::/48', '2a03:2881:4004::/48', '2a03:2881:4006::/48', '2a03:2881:4007::/48', '2a03:2881:4009::/48'
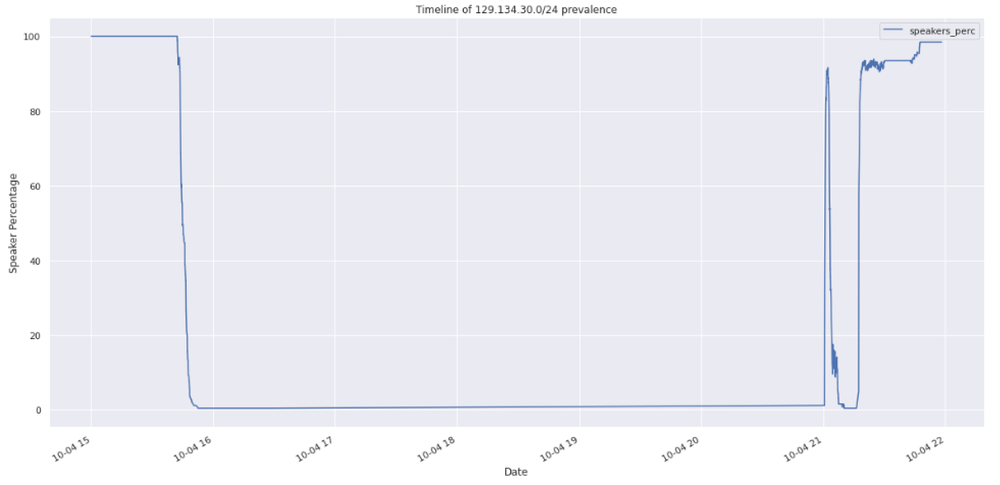
129.134.30.0/24 visibility, Qrator.Radar data
At that moment, when the Facebook nameservers became unreachable because of routes withdrawn from the BGP announcements, millions of clients (in a client-server perspective) started their repeating attempts to query the already unreachable servers.
What happened next was the combination of DNS, BGP and hands.

“A netmask joke”, credit Mark Dunne
In an official statement a later, when everybody in the world found themselves having too much spare time, Facebook said the outage resulted from a configuration change, sending a cascading effect and causing the entire Facebook inner and outer infrastructure to halt.
For more than 5 hours.
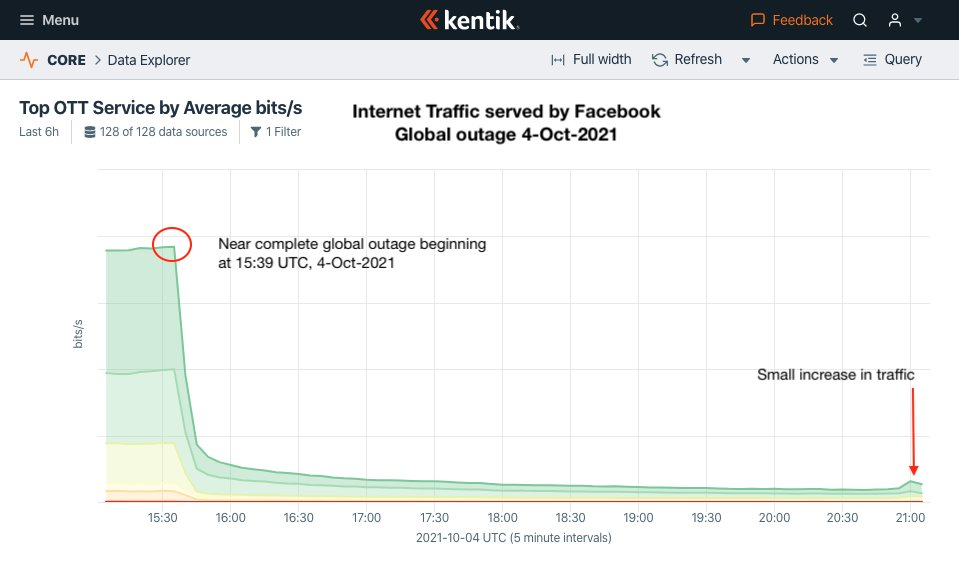
Credit: Doug Madory, Kentik
Especially interesting was how the global Internet infrastructure reacted to such a disappearance. In short - badly.
That is where DNS mechanics combined with the human factor kick in.
Cache Negative: This value controls negative caching time, which is how long a resolver will cache an NXDOMAIN Name Error. The maximum value allowed by RFC 2308 for this parameter is 24 hours (86400 seconds).
Note that it states only the maximum allowed parameter value, not the minimum, which could be 0.
DNS resolvers caching the SERVFAIL and NXDOMAIN responses amplified the storm, as they too needed to check the upper-level DNS servers. If NXDOMAIN hit cache is X CPU cycles, then an NXDOMAIN cache miss is X x Y CPU cycles, where Y could be a huge number because of recursion and shared resources.
Getting an error in the browser makes the user want to try again. Applications start retrying their queries as well. People unable to access their WhatsApp start looking for other ways to communicate. The flood spills over a vast Internet territory, affecting other resources.
Most of the others - local ISPs. Yesterday, Vodafone reported issues (Czech language) with handling traffic loads in the Czech Republic because of Facebook disappearance. Probably not only because of DNS stress but also because of changing patterns in traffic flows, as users were still trying to access unaffected messengers and social networks, notably Telegram and Twitter.
A Slovakian ISP employee (Blažej Krajňák) reported a massive traffic change on recursive resolvers, saying as it looks like a DDoS attack to DNS servers:
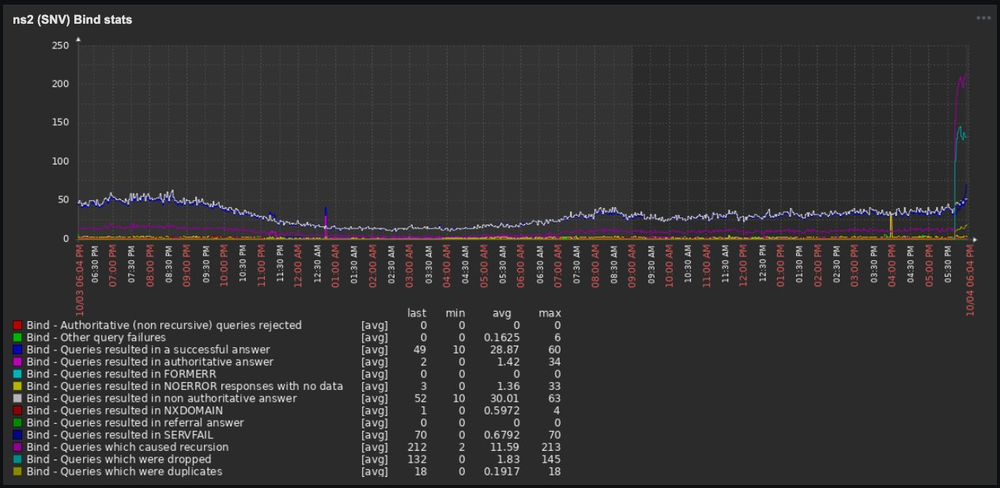
Credit: Blažej Krajňák
At this graph screenshot from the AMS-IX Global Roaming Traffic statistics, you can see how significant is the share of Facebook/Instagram/WhatsApp traffic from the total, something from 10% to 20%:
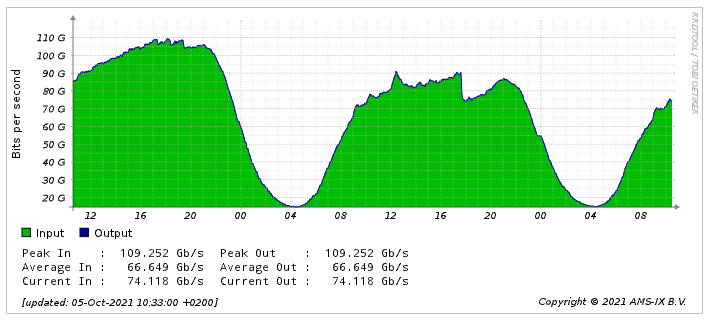
Credit: AMSIX GRX traffic statistics
Brian Krebs also reported that several domain registration companies listed Facebook.com as up for sale because of the automated systems that look for expired/abandoned/vacated domains - a funny consequence of Facebook’s name servers absent from the Internet for such a period.
So, is there anything one can do to mitigate the consequences of such a misconfiguration? Not very much.
It is much better to try preventing misconfigurations in the first place, following the industry best practices in creating and implementing configuration changes, especially on the edge routers of a heavily loaded network.
Yesterday we saw what could happen otherwise.

Credit: Honest Networker